Ober sticht Unter: Der Traffic-Scheduler
Im letzten Post zum Thema „Zeitkritische Netze“ wurde das Thema Quality of Service (QoS) zur Sicherstellung der Übertragung angesprochen. Da QoS ein sehr breites Thema ist, soll hier ein erster Überblick über die gängigen Methoden gezeigt werden, wie Pakete im Falle von Überlastung priorisiert werden.
Zuständig ist hierfür der s. g. Scheduler, der dafür sorgt, dass Pakete, die sich zur Übertragung über einen Ausgangsport einreihen, in der vorgesehenen Reihenfolge behandelt werden.
Die Festlegung der Paketprioritäten, z. B. über DiffServ, CoS oder SRP in AVB/TSN-Netzen soll hier nicht betrachtet werden.
Aufbau
Ein Port (z. B. Switchport) besitzt in Senderichtung einen Puffer um Pakete vor dem Versand zu speichern. Treffen Pakete schneller ein, als der Port diese versenden kann, dient dieser Puffer als Zwischenspeicher.
QoS-fähige Geräte verfügen über mehrere solcher Speicherbereiche (Queues), die über verschiedene Prioritäten verfügen. Der Scheduler ist dafür zuständig, diese Queues gemäß der jeweiligen Prioritäten oder Einstellungen zu entleeren und damit den gepufferten Paketen Sendezeiten zuzuordnen.
Ausgangssituation
In den folgenden Beispielen wird von einem 4-Port-Switch ausgegangen. Drei der Ports (P1-P3) werden für den Empfang von Daten genutzt, welche an Port PE weitergeleitet und über diesen verschickt werden sollen (siehe Abb. 1).
Der Einfachheit halber, gehen wir von einer 1:1-Zuordnung der CoS-Map aus. Das heißt, mit CoS = 1 getaggter Datenverkehr wird auf Queue 1, CoS = 2 auf Queue 2 und CoS = 3 auf Queue 3 geleitet.
Ebenso verzichten wir auf die Komplexität von Byte-Countern und gehen daher davon aus, dass der an Port 1-3 eintreffende Verkehr mit maximaler Geschwindigkeit eintrifft und jedes Paket die selbe Größe hat.
Die folgenden Beschreibungen und Abbildungen sind daher exemplarisch.
Strict Priority Scheduling
Das einfachste Szenario ist das Scheduling nach einem strikten Prioritätsverfahren. Hierbei werden den Queues aufsteigende Prioritäten zugeordnet. Die nummerisch niedrigste Queue erhält dabei die niedrigste, die nummerisch höchste Queue die höchste Priorität.
Der Scheduler arbeitet prinzipiell in einem zyklischen Verfahren. Das heißt, er läuft die Queues absteigend (beginnend bei der höchstwertigen) ab und überprüft, ob sich darin Pakete zum Versand befinden und ob sie für den Versand ausgewählt werden dürfen. Nach Abschluss der Prüfung aller Queues, wird wieder von vorne begonnen.
Abb. 1 zeigt das zeitgleiche Eintreffen von Paketen an den Ports 1-3 zum Zeitpunkt t0.
Da alle Ports mit der selben Geschwindigkeit arbeiten, kommt es nun zu einem Engpass. Der Ausgangsport PE kann die Daten nicht wieder so schnell versenden, wie sie eintreffen.
Die Pakete werden also gemäß ihren Prioritäten in der jeweiligen Queue gepuffert und der Scheduler beginnt zu arbeiten.
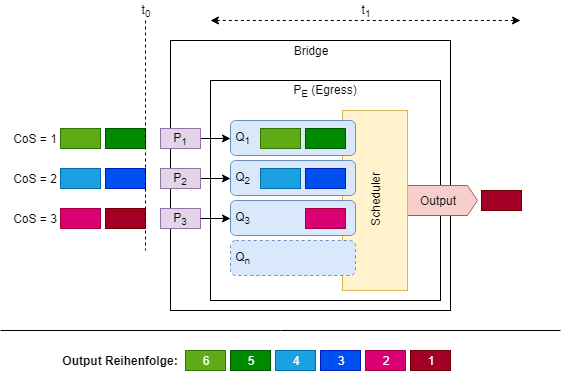
t1 zeigt hierbei den Zustand, nachdem der Scheduler das erste Paket für den Versand ausgewählt hat. Die Queue mit der höchsten Priorität, in welcher sich Daten befinden, ist Q3. Im Strict Priority Verfahren werden niederwertige Queues erst behandelt, nachdem die höherwertigen keine Daten mehr zum Versand beinhalten.
Der Scheduler wird also bei Q3 beginnen und erst zu der Abarbeitung von Q2 wechseln, wenn Q3 vollständig geleert ist. Analog hierzu wird Q1 erst behandelt, nachdem Q2 vollständig leer ist.
Mit diesem Verfahren kann also gewährleistet werden, dass Datenverkehr mit hoher Priorität absolut vorrangig behandelt wird.
Weighted Round-Robin Scheduling
Das o. g. Strict Priority Verfahren hat jedoch den Nachteil, dass es extrem „unfair“ ist. Lastet Datenverkehr mit hoher Priorität den Zielport vollständig aus, so hat niederwertiger Verkehr keine Chance versendet zu werden. Aus diesem Grund können die Queues mit dem Weighted Round-Robin-Verfahren (WRR) gewichtet werden.
Abb. 2 zeigt das vorherige Beispiel mit dem Unterschied, dass Queue 1-3 nun als WRR-Queues mit unterschiedlichen Wertigkeiten konfiguriert wurden. Die Wertigkeiten ändern nichts an der Abarbeitungsreihenfolge, jedoch an der effektiven Menge der zum Versand selektierten Pakete.
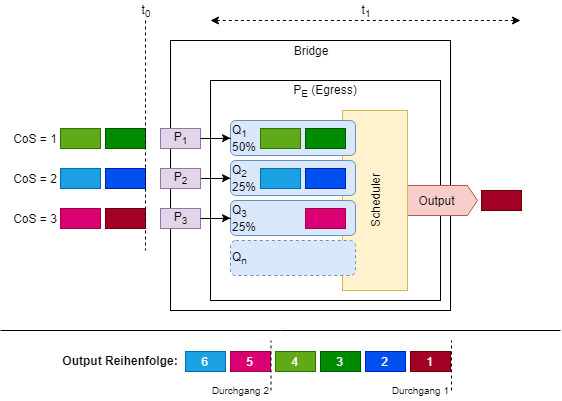
In diesem Beispiel darf Q1 (Wertigkeit = 50%) somit doppelt so häufig (oder genauer, solange) Pakete versenden als Q2 oder Q3 (jeweils Wertigkeit = 25%), trotz dass Q1 prinzipiell die niedrigste Priorität hat.
Der Scheduler betrachtet auch hier als erstes Q3 und selektiert auch von dort das erste Paket zum Versand, allerdings wird diese Queue (aus Byte- bzw. Zeitsicht) nur halb solange beachtet wie Q1.
Strict-WRR Scheduling
In der Praxis kommt es jedoch häufig vor, dass weder eine ausschließlich strikte noch eine faire Behandlung der Weg zum Ziel ist. Absolut kritischer Datenverkehr (PTP, VoIP, Management) soll nicht fair weitergeleitet werden, sondern hat absolute Priorität ggü. der Präsentation, die ein Mitarbeiter gerade vom Fileserver lädt.
Jedoch ist die Präsentation (relativ) wichtiger als das Surfen im Web, das Surfen verursacht aber im Vergleich mehr Traffic. Beides soll jedoch zeitgleich zufriedenstellend funktionieren. Hier empfiehlt sich wiederum WRR.
Wie fast immer liegt die Lösung in der Mitte: Das folgende Beispiel zeigt die Mischung von striktem und fairem Scheduling (Abb. 3).
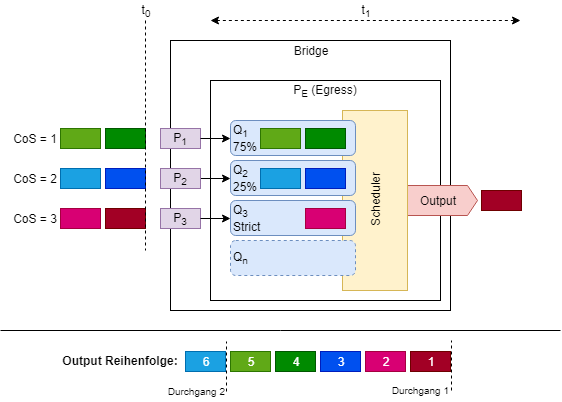
Weisen wir VoIP-Verkehr die Priorität CoS = 3, File-Transfer CoS = 2 und Web-Traffic CoS = 1 zu und bestimmen Queue 1 und 2 als WRR-Queue und Queue 3 als Strict Priority Queue, so erreichen wir Folgendes:
- VoIP-Traffic wird immer absolut priorisiert behandelt
- File-Transfer ist wichtiger als Web-Traffic, erhält aber im Überlastungsfall nur 1/4 der übrigen Bandbreite
- Web-Traffic ist unwichtiger als File-Transfer, erhält aber im Überlastungsfall 3/4 der übrigen Bandbreite
Credit-based Shaping
Bisher betrachteten wir Fälle, in denen wir bestimmten Traffic ggü. anderem Traffic priorisierten. Dem Einen oder Anderen mag aufgefallen sein, dass bisher nie die Rede von absoluten Bandbreiten sondern immer nur simplen Prioritäten oder Verhältnissen war.
Wie werden nun Fälle behandelt, bei denen absolute Bandbreiten reserviert oder Latenzgrenzen eingehalten werden müssen?
Hierzu definiert 802.1Q Annex L den Credit-based Shaper (CBS). Der wesentliche Unterschied zu den oben genannten Scheduling-Verfahren besteht darin, dass der CBS in der Lage ist Latenzen und Bandbreiten zu garantieren, diese aber im selben Zug auch begrenzt.
Der Name rührt daher, dass während der Zeit, in der die CBS-Queue vom Scheduler nicht beachtet wird oder aber keine Daten zum Versand bereitliegen, die Queue Credits „verdient“. Umgekehrt „kostet“ das Abarbeiten der Queue Credits.
Die Queue bekommt, während sie auf Abarbeitung wartet oder keine Daten zum Versand bereithält, Credits mit der Geschwindigkeit idleSlope bis zum Limit hiCredit gutgeschrieben.
idleSlope entspricht der reservierten relativen Bandbreite multipliziert mit der Portgeschwindigkeit.
So beträgt idleSlope beispielsweise 75 Mbit/s bei einer Reservierung von 75% von 100 Mbit/s.
Kommt der Zeitpunkt der Abarbeitung und Daten liegen zum Versand bereit, so wird Paket um Paket aus der Queue „unter Bezahlung“ versandt, bis die Queue leer ist oder aber nach Versand eines Pakets das Guthaben <0 ist. Im letzten Fall müssen die verbleibenden Pakete darauf warten, bis das Guthaben wieder ≥0 ist und sich der Scheduler erneut um die Queue kümmert.
Um das Verfahren fair zu gestalten und dennoch die Bandbreiten- und Latenzanforderungen zu garantieren, laufen die Berechnungen in Zeitschlitzen von 125 µs (im Standard) ab.
idleSlope beträgt also nicht tatsächlich 75 Mbit pro Sekunde sondern 75 Mbit/s × 10-6 × 125 pro 125 Mikrosekunden.
Benötigt eine CBS-Queue nicht alle vorhandenen Credits, so kann die übrig gebliebene Bandbreite von anderen Nicht-CBS-Queues verwendet werden.
Andere CBS-Queues dürfen diese nicht verwenden, da dadurch ihre Reservierung überschritten werden würde.
Die Steuerung der Reservierung läuft im Falle von AVB/TSN automatisch ab. Hierzu werden s. g. SRP-Domains (Stream Reservation Protocol) im Netzwerk etabliert, welche einheitliche Klassenanforderungen auf allen involvierten Netzwerkgeräten anfordern. SRP kümmert sich darum, dass das Erfüllen einer Reservierung, als auch ein Fehler zu den Teilnehmern kommuniziert wird.
Ein Fehler wäre beispielsweise, wenn eine Reservierung nicht erfüllt werden kann, da diese mit bereits bestehenden Reservierungen zu einer „Überreservierung“ der tatsächlichen Portgeschwindigkeit führen würde.
Mit SRP wird sichergestellt, dass die Anforderungen vom Anfang bis zum Ende, also vom Talker zum Listener, auch tatsächlich erfüllt werden.